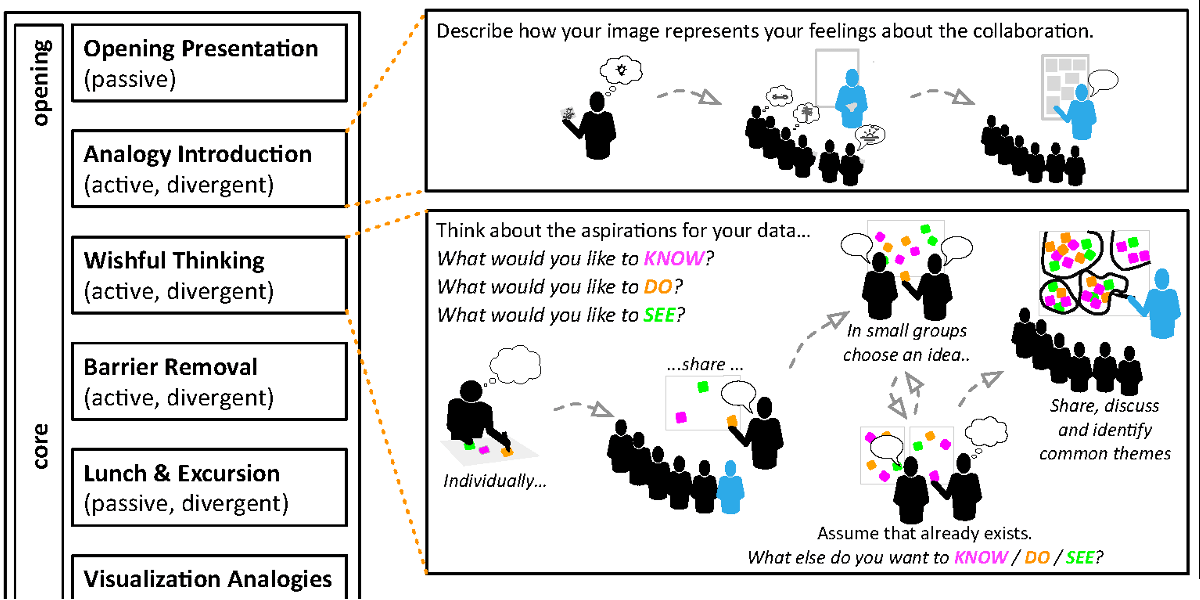
Abstract
Applied visualization researchers often work closely with domain collaborators to explore new and useful applications of visualization. The early stages of collaborations are typically time consuming for all stakeholders as researchers piece together an understanding of domain challenges from disparate discussions and meetings. A number of recent projects, however, report on the use of creative visualization-opportunities (CVO) workshops to accelerate the early stages of applied work, eliciting a wealth of requirements in a few days of focused work. Yet, there is no established guidance for how to use such workshops effectively. In this paper, we present the results of a 2-year collaboration in which we analyzed the use of 17 workshops in 10 visualization contexts. Its primary contribution is a framework for CVO workshops that: 1) identifies a process model for using workshops; 2) describes a structure of what happens within effective workshops; 3) recommends 25 actionable guidelines for future workshops; and 4) presents an example workshop and workshop methods. The creation of this framework exemplifies the use of critical reflection to learn about visualization in practice from diverse studies and experience.Citation
Ethan Kerzner,
Sarah Goodwin,
Jason Dykes,
Sara Jones,
Miriah Meyer
A Framework for Creative Visualization-Opportunities Workshops
IEEE Transactions on Visualization and Computer Graphics (InfoVis), 25(1): 748-758, doi:10.1109/TVCG.2018.2865241, 2019.
BibTeX
@article{2018_infovis_creative-workshops,
title = {A Framework for Creative Visualization-Opportunities Workshops},
author = {Ethan Kerzner and Sarah Goodwin and Jason Dykes and Sara Jones and Miriah Meyer},
journal = {IEEE Transactions on Visualization and Computer Graphics (InfoVis)},
publisher = {IEEE},
doi = {10.1109/TVCG.2018.2865241},
volume = {25},
number = {1},
pages = {748-758},
year = {2019}
}
Acknowledgements
We are grateful to the participants, facilitators, and fellow researchers in all of our workshops. We thank the following people for their feedback and contributions to this work: the anonymous reviewers, Graham Dove, Tim Dwyer, Peter Hoghton, Christine Pickett, David Rogers, Francesca Samsel, members of the Vis Design Lab at the University of Utah, and members of the giCentre at City, University of London. This work was supported in part by NSF Grant IIS- 1350896.