Abstract
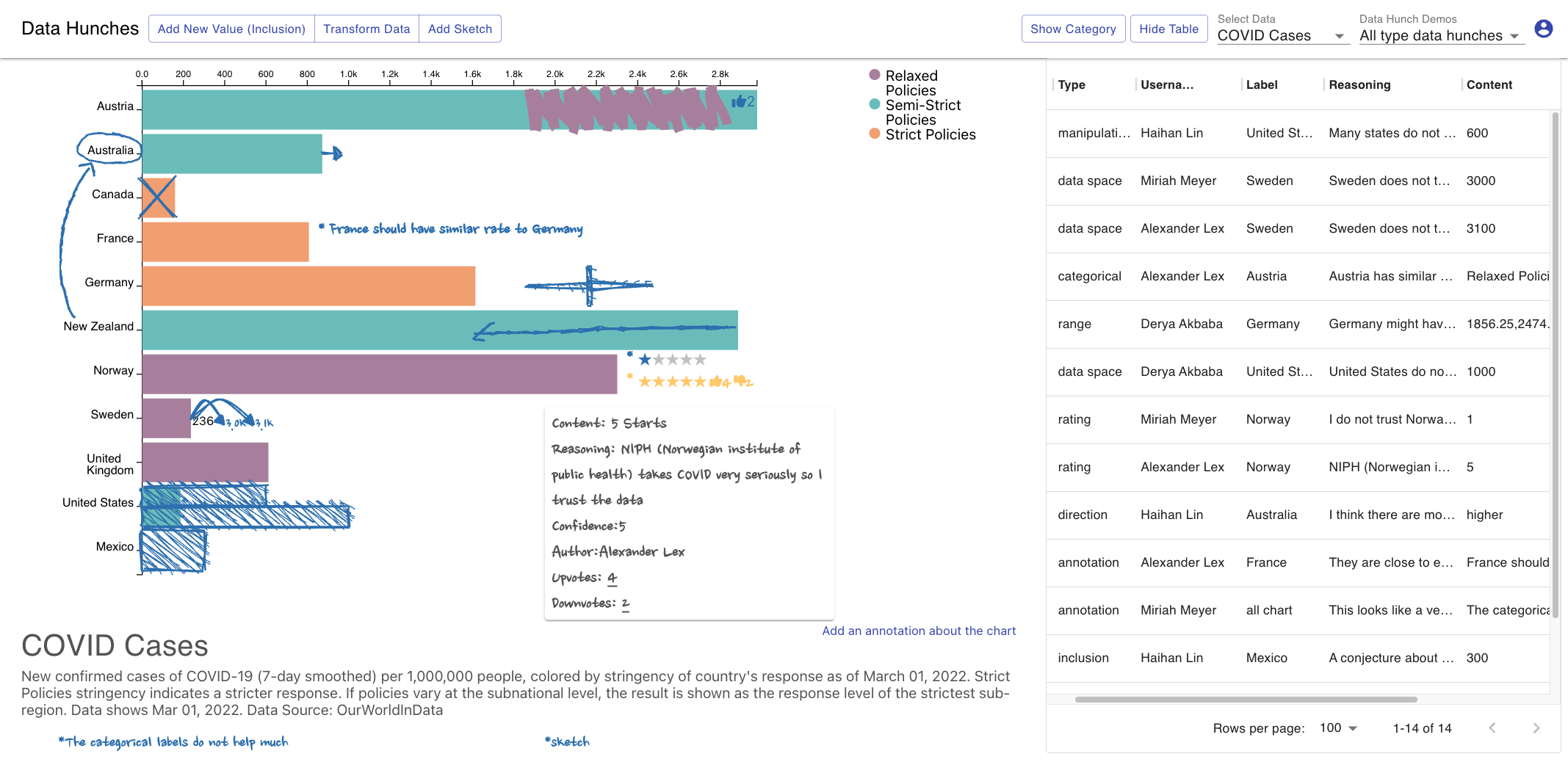
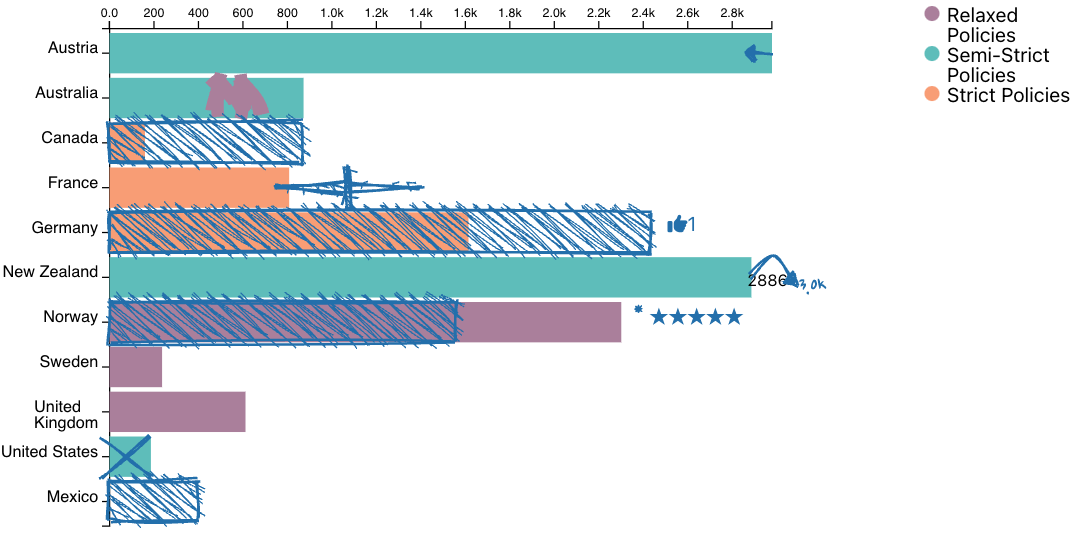
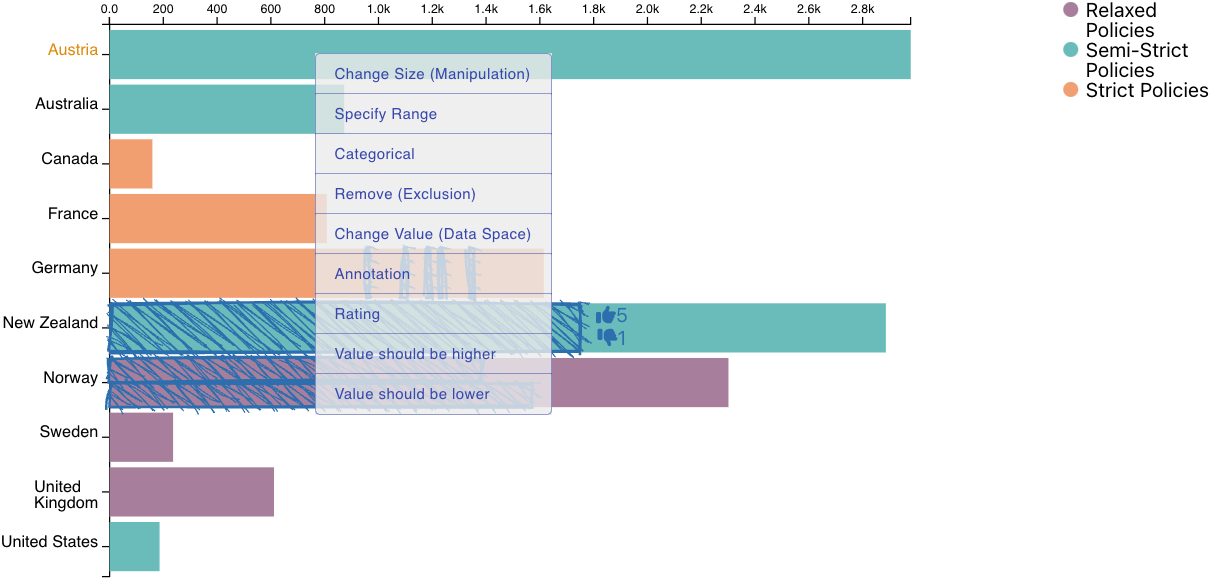
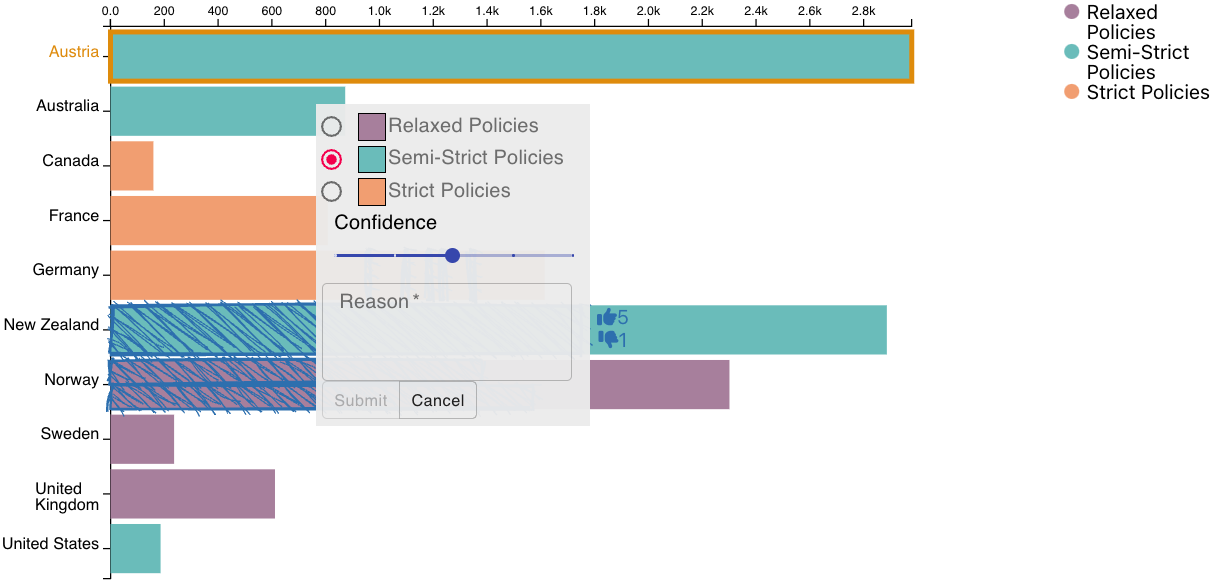
The trouble with data is that it frequently provides only an imperfect representation of a phenomenon of interest. Experts who are familiar with their datasets will often make implicit, mental corrections when analyzing a dataset, or will be cautious not to be overly confident about their findings if caveats are present. However, personal knowledge about the caveats of a dataset is typically not incorporated in a structured way, which is problematic if others who lack that knowledge interpret the data. In this work, we define such analysts' knowledge about datasets as data hunches. We differentiate data hunches from uncertainty and discuss types of hunches. We then explore ways of recording data hunches, and, based on a prototypical design, develop recommendations for designing visualizations that support data hunches. We conclude by discussing various challenges associated with data hunches, including the potential for harm and challenges for trust and privacy. We envision that data hunches will empower analysts to externalize their knowledge, facilitate collaboration and communication, and support the ability to learn from others' data hunches.Citation
Haihan Lin,
Derya Akbaba,
Miriah Meyer,
Alexander Lex
Data Hunches: Incorporating Personal Knowledge into Visualizations
IEEE Transactions on Visualization and Computer Graphics (VIS), 29(1): 504-514, doi:10.1109/TVCG.2022.3209451, 2022.
BibTeX
@article{2022_vis_data_hunches,
title = {Data Hunches: Incorporating Personal Knowledge into Visualizations},
author = {Haihan Lin and Derya Akbaba and Miriah Meyer and Alexander Lex},
booktitle = {IEEE Transactions on Visualization and Computer Graphics (VIS)},
doi = {10.1109/TVCG.2022.3209451},
pages = {504-514},
volume = {29},
number = {1},
year = {2022}
}
Acknowledgements
We wish to thank Anders Ynnerman, Ben Shneiderman, Ryan Metcalf, and the Visualization Design Lab for fruitful discussions and feedback. This work was supported by the National Science Foundation (OAC1835904, IIS 1751238), ARUP Laboratories, and by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation.
Images
These images are not part of the original paper and licensed using CC BY 4.0. If you use these images, please cite the paper. Click on the images for full resolution.